SUBQUERY
하나의 SELECT 문장의 절 안에 포함된 또 하나의 SELCET 문장이다.
메인쿼리를 위해 보조하는 역할이며 SELECT, FROM, WHERE, HAVING 절에서 사용가능
서브쿼리 사용 예시 -
1) 사원명이 노옹철인 사람의 부서코드 조회
SELECT DEPT_CODE FROM EMPLOYEE
WHERE EMP_NAME='노옹철';
2) 부서코드가 D9인 직원을 조회
SELECT EMP_NAME, DEPT_CODE FROM EMPLOYEE
WHERE DEPT_CODE = 'D9';
3) 부서코드가 노옹철사원과 같은 소속의 직원 명단 조회
SELECT EMP_NAME, DEPT_CODE FROM EMPLOYEE
WHERE DEPT_CODE = (SELECT DEPT_CODE FROM EMPLOYEE WHERE EMP_NAME='노옹철')위에 같이, 두개의 쿼리를 하나로 작성하는 것이 SUBGUERY이다.
해석하는 방법은 서브쿼리 먼저 해석하고, 메인쿼리를 해석하는 것이다.
💡 서브쿼리유형
- 단일행(+단일열) 서브쿼리 : 서브쿼리의 조회 결과 값을 개수가 1개일 때
- 다중행(+단일열) 서브쿼리 : 서브쿼리의 조회 결과 값의 개수가 여러개일 때
- 다중열 서브쿼리 : 서브쿼리의 SELSECT절에 나열된 항목수가 여러개 일 때
- 다중행 다중열 서브쿼리 : 조회결과 행 수와 열 수가 여러개일 때
ㄴ 서브쿼리를 먼저 해석을 하고 메인쿼리를 나중에 해석을 했다.
- 상관 서브쿼리 : 서브쿼리가 만든 결과 값을 메인 쿼리가 비교 연산할 때
메인 쿼리 테이블의 값이 변경되면 서브쿼리의 결과 값도 바뀌는 서브쿼리
- 스칼라 서브쿼리 : 상관쿼리 이면서 결과 값이 하나인 서브쿼리
* 서브쿼리 유형에 따라 서브쿼리 앞에 붙은 연산자가 다름
서브쿼리 유형
1. 단일행(+단일열)서브쿼리 (SINGLE ROW SUBQUERY)
서브쿼리의 조회 결과 값의 개수가 1개인 서브쿼리
단일행 서브쿼리 앞에는 비교연산자 사용
<,>,<=,>=,=,!=/^=/<>
1) 전 직원의 급여평균보다 많은 급여를 받는 직원의 이름, 직급, 부서, 급여를 직급 순으로 정렬하여 조회
SELECT EMP_NAME,JOB_CODE,DEPT_CODE,SALARY
FROM EMPLOYEE
WHERE (SELECT AVG(SALARY) FROM EMPLOYEE )< SALARY
ORDER BY JOB_CODE;2) 노옹철 사원의 급여보다 많이 받는 직원의 사번, 이름, 부서, 직급, 급여를 조회
SELECT EMP_ID,EMP_NAME,DEPT_CODE,JOB_CODE,SALARY
FROM EMPLOYEE
WHERE SALARY>(SELECT SALARY FROM EMPLOYEE WHERE EMP_NAME = '노옹철');
부서별(부서가 없는 사람 포함) 급여의 합계 중 가장 큰 부서의 부서명, 급여 합계를 조회
1) 부서별 급여 합 중 가장 큰값 조회 (부서별 급여 합 1등 구하기)
SELECT MAX(SUM(SALARY))
FROM EMPLOYEE
GROUP BY DEPT_CODE;2) 부서별로 급여 합이 17700000인 부서명과 급여 합 조회
SELECT DEPT_TITLE, SUM(SALARY)
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON (DEPT_CODE = DEPT_ID)
GROUP BY DEPT_TITLE
HAVING SUM(SALARY)=17700000;3) 위에 두서브쿼리를 합 부서별 급여 합이 큰 부서의 부서명, 급여 합 조회
SELECT DEPT_TITLE, SUM(SALARY)
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON (DEPT_CODE = DEPT_ID)
GROUP BY DEPT_TITLE
HAVING SUM(SALARY)=(SELECT MAX(SUM(SALARY))
FROM EMPLOYEE
GROUP BY DEPT_CODE);
2. 다중행 서브쿼리 (MULTI ROW SUBQUERY)
서브쿼리의 조회 결과 값의 개수가 여러행일 때
다중행 서브쿼리 앞에는 일반 비교연산자 사용 할 수 없으며 다중행 서브쿼리에서 사용할 수 있는 연산자는 다음과 같다.
1. IN / NOT IN : 여러 개의 결과값 중에서 한 개라도 일치하는 값이 있다면
혹은 없다면 이라는 의미(가장 많이 사용!)
부서별 최고 급여를 받는 직원의 이름 직급 부서 급여를 부서순으로 정렬하여 조회
SELECT EMP_NAME,JOB_CODE,DEPT_CODE,SALARY
FROM EMPLOYEE
WHERE SALARY IN (SELECT MAX(SALARY)
FROM EMPLOYEE
GROUP BY DEPT_CODE)
ORDER BY DEPT_CODE;
사수에 해당하는 직원에 대해 조회 사번, 이름, 부서명, 직급명 구분(사수/직원)
1) 사수에 해당하는 사원번호 조회
SELECT DISTINCT MANAGER_ID
FROM EMPLOYEE
WHERE MANGER_ID IS NOT NULL;2) 직원의 사번, 이름, 부서명, 직급명 조회 (부서 없는 사람 포함)
SELECT EMP_ID, EMP_NAME, DEPT_TITLE, JOB_NAME
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON (DEPT_CODE,DEPT_ID)
JOIN JOB USING (JOB_CODE);3) 사수에 해당하는 직원에 대한 정보 추출 조회
SELECT EMP_ID,EMP_NAME,DEPT_TITLE, JOB_NAME
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON (DEPT_CODE=DEPT_ID)
JOIN JOB USING (JOB_CODE)
WHERE EMP_ID IN (SELECT DISTINCT MANAGER_ID
FROM EMPLOYEE
WHERE MANAGER_ID IS NOT NULL);4) 사원에 해당하는 직원에 대한 정보 추출 조회
- 3)은 사수에 해당하는 직원 정보를 호출하는 SQL문이다. 그럼 사원이라면 NOT을 붙여 부정을 해주면 된다.
SELECT EMP_ID,EMP_NAME,DEPT_TITLE, JOB_NAME
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON (DEPT_CODE=DEPT_ID)
JOIN JOB USING (JOB_CODE)
WHERE EMP_ID NOT IN (SELECT DISTINCT MANAGER_ID
FROM EMPLOYEE
WHERE MANAGER_ID IS NOT NULL);5) 3번, 4번 조회 결과를 한개로 합칠 수 있다. SELECT문도 서브쿼리 사용할 수 있다.
-- *SELECT 절에도 서브쿼리를 사용할 수 있다.
SELECT EMP_ID,EMP_NAME,DEPT_TITLE, JOB_NAME,
CASE WHEN EMP_ID IN (SELECT DISTINCT MANAGER_ID
FROM EMPLOYEE
WHERE MANAGER_ID IS NOT NULL)
THEN '사수'
ELSE '사원'
END 구분
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON (DEPT_CODE=DEPT_ID)
JOIN JOB USING(JOB_CODE);6) 3번, 4번 UNION을 이용해서 합칠 수도 있다.
SELECT EMP_ID,EMP_NAME,DEPT_TITLE, JOB_NAME
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON (DEPT_CODE=DEPT_ID)
JOIN JOB USING (JOB_CODE)
WHERE EMP_ID IN (SELECT DISTINCT MANAGER_ID
FROM EMPLOYEE
WHERE MANAGER_ID IS NOT NULL)
UNION --합집합(2개의 RESULT SET 하나로 합침)
SELECT EMP_ID,EMP_NAME,DEPT_TITLE, JOB_NAME
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON (DEPT_CODE=DEPT_ID)
JOIN JOB USING (JOB_CODE)
WHERE EMP_ID NOT IN (SELECT DISTINCT MANAGER_ID
FROM EMPLOYEE
WHERE MANAGER_ID IS NOT NULL);
2. ANY, < ANY : 여러개의 결과값 중에서 한개라도 큰 / 작은 경우
가장 작은 값보다 큰가? / 가장 큰 값 보다 작은가?
1) 직급이 대리인 직원들의 사번 이름 직급명 급여 조회
SELECT EMP_ID,EMP_NAME, JOB_NAME, SALARY
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME ='대리';2) 직급이 과장인 직원들의 사번 이름 직급명 급여 조회
SELECT EMP_ID,EMP_NAME, JOB_NAME, SALARY
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME ='과장';3) 대리 직급의 직원들 중에서 과장 직급의 최소 급여보다 많이 받는 직원
3-1) MIN을 이용하여 단일행 서브쿼리를 만듦
SELECT EMP_ID,EMP_NAME, JOB_NAME, SALARY
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME='대리'
AND SALARY > (SELECT MIN(SALARY)
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME ='과장');3-2)ANY를 이용하여 과장 중 가장 급여가 적은 직원 초과하는 대리 조회
SELECT EMP_ID,EMP_NAME, JOB_NAME, SALARY
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME='대리'
AND SALARY > ANY(SELECT (SALARY)
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME ='과장');
3. ALL, < ALL : 여러개의 결과값의 모든 값보다 큰 / 작은 경우
가장 큰 값 보다 큰가? / 가장 작은 값 보다 작은가?
차장 직급의 급여의 가장 큰 값보다 많이 받는 과장 직급의 직원 사번, 이름, 직급, 급여를 조회하세요
SELECT EMP_ID,EMP_NAME, JOB_NAME, SALARY
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME='과장' AND SALARY > ALL (SELECT SALARY
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
WHERE JOB_NAME ='차장');
4. EXISTS / NOT EXISTS : 값이 존재하는가? / 존재하지 않는가
3. 다중열 서브쿼리 (MULTI ROW SUBQUERY)
서브쿼리 SELECT절에 나열된 컬럼 수가 여러개 일때
퇴사한 여직원과 같은 부서, 같은직급에 해당하는 사원의 이름, 직급,부서,입사일 조회
1)퇴사한 여직원 조회
SELECT EMP_NAME,JOB_CODE,DEPT_CODE,HIRE_DATE
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO,8,1)=2
AND ENT_YN = 'Y';2)퇴사한 여직원과 같은 부서, 같은 직급(다중 열 서브쿼리)
SELECT EMP_NAME,JOB_CODE,DEPT_CODE,HIRE_DATE
FROM EMPLOYEE
WHERE DEPT_CODE = (SELECT DEPT_CODE
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO,8,1)=2
AND ENT_YN = 'Y')
AND JOB_CODE = (SELECT JOB_CODE
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO,8,1)=2
AND ENT_YN = 'Y');
SELECT EMP_NAME,JOB_CODE,DEPT_CODE,HIRE_DATE
FROM EMPLOYEE
WHERE (DEPT_CODE,JOB_CODE) = (SELECT DEPT_CODE,JOB_CODE -- 다중열 서브쿼리
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO,8,1)=2
AND ENT_YN = 'Y');4. 다중행 다중열 서브쿼리
서브쿼리 조회 결과 행 수와 열 수가 여러개 일때
본인 직급의 평균 급여를 받고 있는 직원의 사번, 이름, 직급, 급여를 조회하시오
단, 급여와 급여평균은 만원 단위로 계산하세요
1) 급여를 200, 600만 받는 직원
SELECT EMP_ID,EMP_NAME,JOB_CODE,SALARY
FROM EMPLOYEE
WHERE SALARY IN ('2000000','6000000');2) 직급별 평균 급여
SELECT JOB_CODE,TRUNC(AVG(SALARY),-4)
FROM EMPLOYEE
GROUP BY JOB_CODE;✔ TRUNC 절삭 !
--TRUNC(숫자|컬럼명 [,위치]) :특정 위치 아래를 버림 (절삭)
SELECT TRUNC(123.456,1), TRUNC(123.456,-1)
FROM DUAL;
123.4 /120
3) 본인 직급의 평균 급여를 받고 있는 직원
SELECT EMP_ID,EMP_NAME,JOB_CODE,SALARY
FROM EMPLOYEE
WHERE (JOB_CODE , SALARY)IN (SELECT JOB_CODE,TRUNC(AVG(SALARY),-4)
FROM EMPLOYEE
GROUP BY JOB_CODE);
5. 상(호연)관 서브쿼리 ( 메인 쿼리 1행 씩 우선 해석, 서브쿼리 나중에 해석)
상관쿼리는 메인쿼리가 사용하는 테이블값을 서브쿼리가 이용해서 결과를 바꿈
메인 쿼리의 테이블값이 변경되면 서브쿼리의 결과값도 변경되는 구조이다.
상관 쿼리는 먼저 메인쿼리 한행을 조회하고 서브쿼리의 조건이 충족하는지 확인하여 SELCET 진행한다.
1) 메인쿼리 1행 해석
2) 해석된 메인쿼리 1행을 이용해 서브쿼리 조회
3) 서브쿼리 결과를 이용해서 메인쿼리 해석 중인 1행을 대상으로 조회
사수가 있는 직원의 사번, 이름, 부서명, 사수사번 조회
SELECT EMP_ID,EMP_NAME,DEPT_TITLE,MANAGER_ID
FROM EMPLOYEE MAIN
LEFT JOIN DEPARTMENT ON (DEPT_CODE = DEPT_ID)
WHERE EXISTS(SELECT EMP_ID FROM EMPLOYEE SUB
WHERE MAIN.MANAGER_ID =SUB.EMP_ID);6. 스칼라 서브쿼리
SELECT절에 사용되는 서브쿼리 결과를 1행(단일행)만 반환
-> SELECT 절에 작성하는 단일행 서브쿼리 SQL에서 단일 값을 가르켜 '스칼라'라고 함
직원의 이름, 급여, 평균 급여를 조회해라
SELECT EMP_NAME,SALARY,(SELECT FLOOR(AVG(SALARY)) FROM EMPLOYEE) 평균
FROM EMPLOYEE;
위에, 전체 평균급여를 조회하는 식인데,
전체 평균에 대해서 조회하게 되었다 만약 조건을 걸고 구하고 싶다면 아래 쿼리문처럼 작성하면 된다.
각 직원들이 속한 직급의 급여 평균 조회
SELECT EMP_NAME,SALARY,JOB_CODE,(SELECT FLOOR(AVG(SALARY)) FROM EMPLOYEE SUB
WHERE SUB.JOB_CODE=MAIN.JOB_CODE)평균
FROM EMPLOYEE MAIN;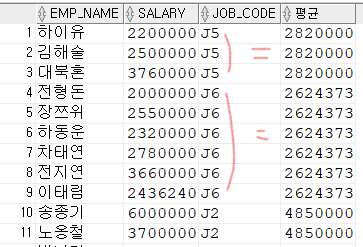
모든 사원의 사번, 이름,관리자사번, 관리자명을 조회 단 관리자가 없는 경우 없으로 표시 (스칼라+상관쿼리)
SELECT EMP_ID,EMP_NAME,NVL(MANAGER_ID,'없음'),
NVL((SELECT EMP_NAME FROM EMPLOYEE E2 WHERE E1.MANAGER_ID = E2.EMP_ID),'없음')관리자명
FROM EMPLOYEE E1;7. 인라인뷰 서브쿼리 (INLINE-VIEW)
FROM절에서 서브쿼리를 사용하는 경우로 서브쿼리가 만든 결과의 집합(RESULT SET)을 테이블 대신에 사용한다.
인라인뷰를 활용한 TOP-N분석 전 직원 중 급여가 높은 상위 5명의 순위, 이름, 급여 조회
1) 직원 중 급여 높은 순으로 조회
SELECT EMP_NAME,SALARY
FROM EMPLOYEE
ORDER BY SALARY DESC;2) 조회되는 행 앞에 1부터 순서대로 1씩 증가하는 번호 붙이기
✔ ROWNUM = 행 번호를 나타내는 가상 컬럼(1부터 1씩 증가)
SELECT ROWNUM, EMP_NAME
FROM EMPLOYEE;
3) ROWNUM을 조건에 사용해서 상위 5명 조회
SELECT ROWNUM, EMP_NAME,SALARY
FROM EMPLOYEE
WHERE ROWNUM <= 5
ORDER BY SALARY DESC;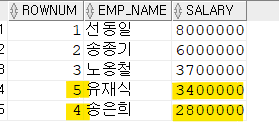
ORDER BY 는 가장 마지막 해석을 하게되어 순서가 바꿨다.
해결하기 위해서 조회결과를 FROM절에 사용한 후 상위 5행만 조회
SELECT ROWNUM,EMP_NAME,SALARY
FROM (SELECT EMP_NAME,SALARY
FROM EMPLOYEE
ORDER BY SALARY DESC) --> FROM절 내부에 포함된 가상의 테이블 == 인라인뷰
WHERE ROWNUM <=5;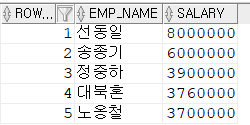
8. WITH
서브쿼리에 이름을 붙여주고 사용시 이름을 사용하며,
EX. 햄버거 가게를 가면, 주문 즉시 조리하는 것이 아닌 만들어 놓았던것을 주는 형태
즉 사용시 이름을 이용해 바로 사용하여 실행속도가 빨라진다는 장점이 있다.
전 직원의 급여 순위, 이름, 급여 조회
SELECT ROWNUM, EMP_NAME,SALARY
FROM ( SELECT EMP_NAME,SALARY
FROM EMPLOYEE
ORDER BY SALARY DESC);TOP_SAL라는 이름의 서브쿼리를 미리 생성
WITH TOP_SAL AS ( SELECT EMP_NAME,SALARY
FROM EMPLOYEE
ORDER BY SALARY DESC)
SELECT ROWNUM,EMP_NAME,SALARY
FROM TOP_SAL;9. RANK() OVER /DENSE_RANK() OVER
9-1) RANK() OVER
동일한 순위 이후의 등수를 동일한 인원 수 만큼 건너뛰고 순위 계산
EX) 공동 1위가 2명이면 다음순위는 2위가 아닌 3위
SELECT RANK() OVER(ORDER BY SALARY DESC) AS 순위 ,EMP_NAME,SALARY
FROM EMPLOYEE;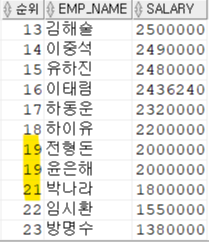
9-2) DENSE_RANK() OVER
동일한 순위 이후의 등수를 이후의 순위로 계산
EX) 공동 1위가 2명이면 다음순위는 2위
SELECT DENSE_RANK() OVER(ORDER BY SALARY DESC) AS 순위 ,EMP_NAME,SALARY
FROM EMPLOYEE;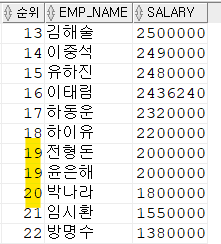
'ON > Oracle' 카테고리의 다른 글
| [Oracle] DAY25_데이터 딕셔너리 | 제약조건 (0) | 2023.05.23 |
|---|---|
| [Oracle] DAY24_데이터 딕셔너리 | CREATE (0) | 2023.05.22 |
| [Oracle] DAY23 _ TCL 트랜잭션 제어 언어 (0) | 2023.05.20 |
| [Oracle] DAY23_DML (0) | 2023.05.19 |
| [Oracle] : DAY22 _JOIN 조인 (0) | 2023.05.19 |